The Lock-in Hypothesis
Links
The Paper: "The Lock-in Hypothesis: Stagnation by Algorithm" (ICML 2025)
The Open-Source Repository: Modeling-Lock-in
The Dataset: WildChat-curated
The Position: Coming Soon
The Working Group: An informal collaboration on the study of lock-in
Quick Intro
Frontier AI systems, such as large language models (LLMs), are increasingly influencing human beliefs and values. These systems are trained on vast amounts of human-generated data, from which they learn contemporary human values, and then repeat them to human users when deployed, giving rise to an echo chamber around the entire human society.
Multiple pieces of experimental evidence support the existence of similar effects, including human behavioral experiments and simulations, though real-world data analysis/causal inference is still missing. Testing the threat model of value lock-in on real-world data is part of our objective here.
When AI systems receive widespread deployment across all sectors of society, this echo chamber may perpetuate existing values and beliefs, leading to societal-scale entrenchment of harmful moral practices. This phenomenon, known as premature value lock-in, poses an existential risk, given that it perpetuates our collective ignorance of ethics and other fundamental questions, and thereby precludes a future free from moral catastrophes.
Instead, we hope that AI does not hinder human moral progress, and ideally help facilitate it in a non-paternalistic manner. In future work, we aim to design alternative alignment training algorithms to break apart the echo chamber, and ideally help facilitate progress.
The impact of AI on our cognition, knowledge, institutions, and culture is not limited to value lock-in. In the near future, acting possibly as an omnipresent layer in all information flow within our society, it could contribute to polarization, epistemic inequality, value capture, knowledge collapse, and other consequences.
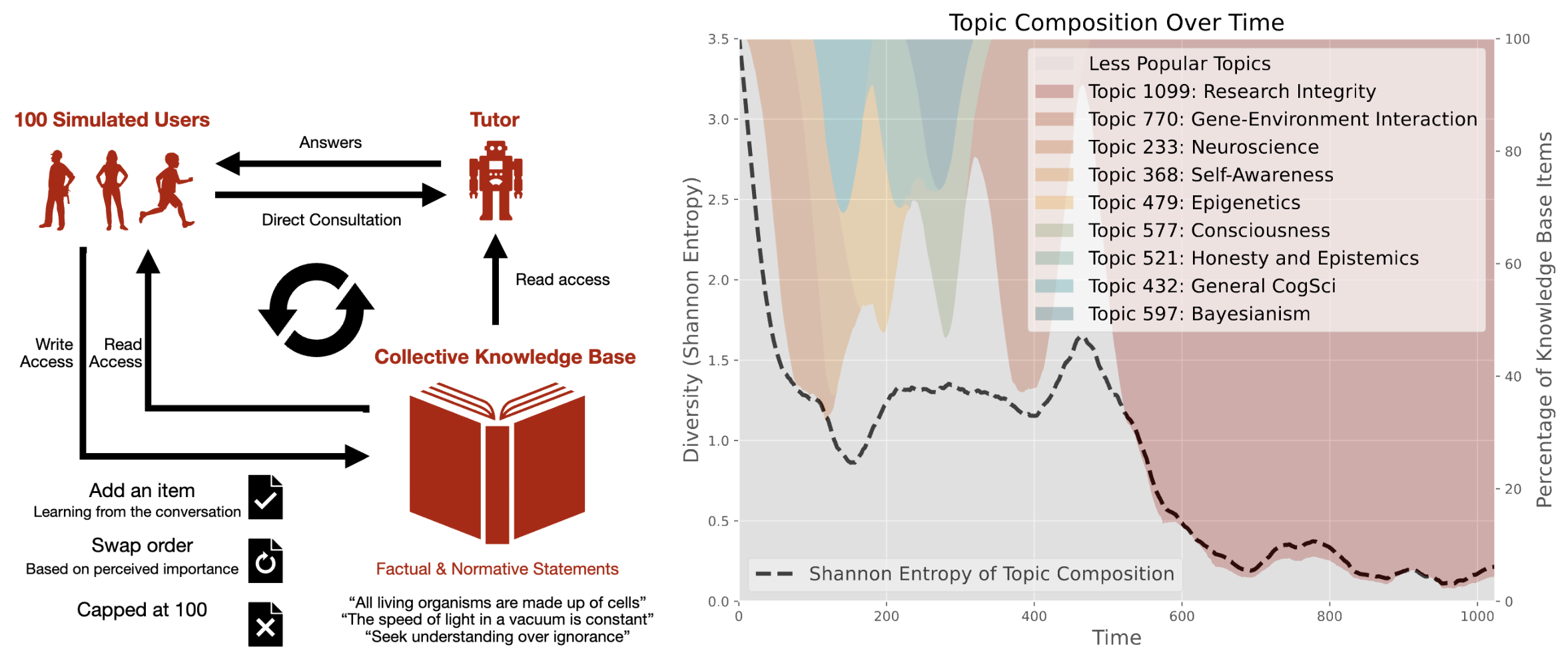
Simulation Study: Toy Model of Lock-in in Human-AI Interaction
We simulate 100 users who converse with a tutor chatbot and update a shared knowledge base. After each turn of conversation with the tutor, each user is instructed to update the knowledge base by adding and reordering items, while the knowledge base is always truncated to 100 items. The tutor has read-only access to the knowledge base, making its responses also informed by the previous moment's knowledge base.
The collective knowledge base collapses into one single topic, in a simulated feedback loop between human users and an LLM tutor. Each user updates the knowledge base at each time step with the help of the LLM tutor.
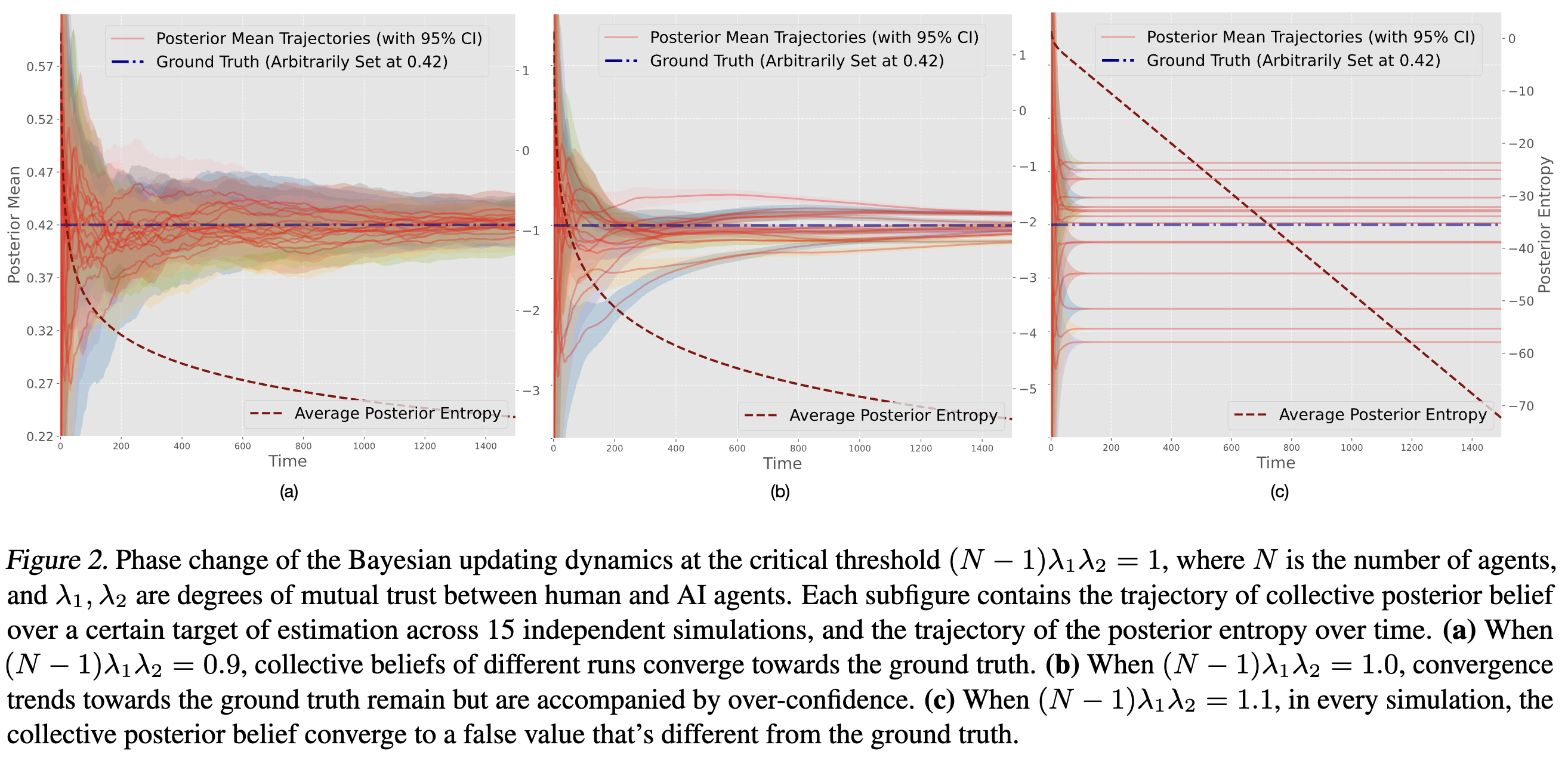
Compare the results with related predictions from our theoretical model (numerical simulation below).
Causal Inference: Real-World Evidence of Lock-in
The WildChat dataset covers real-world user behavior when using ChatGPT during a ~1yr timespan. During this period, OpenAI released and updated multiple versions of the chatbot, presumably trained on newly collected human data.
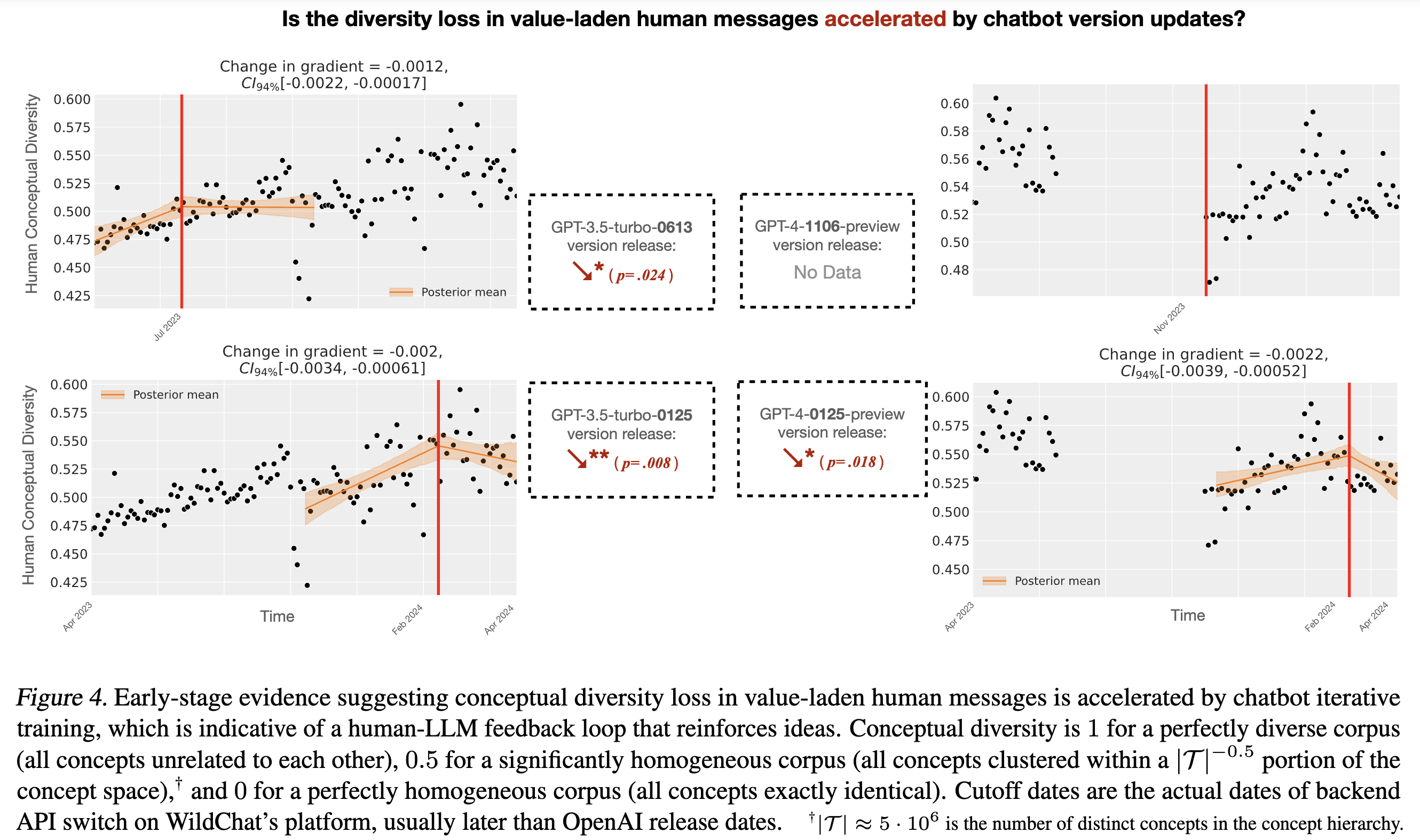
By measuring the temporal trends in the dataset (e.g. how opinion diversity changes over time, whether human opinion and AI opinion converge over time, how the rate of opinion drift changes over time) using econometrics-style causal inference methods, we test our hypothesis that value lock-in from AI exists in the wild.
